Identity and Access Management (IAM)
Official Resources
Main Features
- Centralized control of AWS account.
- Shared access to AWS account.
- Create granular permissions.
- Identity Federation (i.e. log in with Google, Facebook, etc).
- Multi-factor authentication
- Can create temporary access for user/devices and services.
- Can create password rotation policy.
- Supports PCI DSS Compliance: payment card security standards.
Definitions
- User: the end user, such as an employee or bot (Jenkins brewmaster).
- Group: a collection of Users. The Users in the Group inherit the permissions of the Group.
- Policy: a collection of specific permissions to use delineated AWS resources (aka Policy Documents).
- Role: a set of Policies that can be assigned to Users, Groups, or directly to certain AWS Resources (such as EC2).
General
- IAM resources are universal; they are not tied to specific regions.
-
The Root account is created for every new AWS account and has full admin access (dangerous).
- Root users can perform all actions related to IAM.
- Root is needed for very privileged access; in this case, that’s creating a CloudFront key pair, which essentially provides signed access to applications and is a very trusted action.
- General AWS protocol is to provide the least permissions.
- All subsequent users are created with no access, and so must be assigned Roles and/or Policies to become useful.
- New users are assigned (1) an Access Key ID; and (2) Secret Access Keys when first created. Store these safely as they cannot be viewed again from AWS console. These credentials can be used for programmatic (CLI) access to AWS.
- Always set up MFA for the root user of a new account because duh.
- Power user access is a predefined policy that allows access to all AWS services with the exception of group or user management within IAM.
- Power users can work with managed services, but they cannot create (or otherwise manage) IAM users.
Policies
-
Amazon Resource Name (ARN): uniquely identifies any resource in AWS.
- syntax:
arn:partition:service:region:account_id:resource_info - partition: the aws infrastructure partition; typically
aws, but other exists e.g.aws-cnfor China - service: any AWS service, e.g.
s3,ec2, etc - region: the deployment region, e.g.
us-east-1 - account_id: your account id
- resource_info: some resource-specific identifiers
- double colon: omitted value, such as
regionwhen the resource is global in nature (S3, IAM)
- syntax:
-
IAM Policies: JSON document that defines permissions
- Identity policy: attaches to an identity; specifies what an identity can do
- Resource policy: attaches to a resource; specifies who can access a resource and what actions they can perform on it
- Unattached policies have no effect.
- Structured as a list of statements. Each statement matches an AWS API request; i.e. actions that can be taken in the form of an AWS API request.
- Any permission not explicitly allowed it is implicitly denied.
- Explicit deny overrides any other policy.
- Multiple attached policies will be joined by AWS.
- There are AWS-managed (common use case) and customer-managed (custom use case) policies.
-
Permission Boundaries: delegate administration to other users (such as admins or developers).
- Used to prevent privilege escalation or unnecessarily broad permissions.
- Controls the maximum permissions an IAM policy can grant.
- Use cases: developers that create roles for lambda functions, admins creating adhoc users.
Resource Access Manager (RAM)
-
Multi-account strategy: using different AWS accounts to separate concerns such as administration, billing, applications, etc.
- Minimize blast radius of mistakes
- RAM: Allows resource sharing between accounts.
-
Shareable resources:
- App Mesh
- Aurora
- CodeBuild
- EC2: launch EC2 instances in a shared subnet. Subnet isn’t copied, it’s shared!
- EC2 Image Builder
- License Manager
- Resource Groups
- Route 53
Directory Service
- A family of managed services that allow you to connect your AWS resources with an on-premise Microsoft Active Directory; i.e., access AWS resources with existing corporate credentials.
- SSO to any domain-joined EC2 instance.
-
Active Directory: an on-premise directory service that provides a hierarchical database of users, groups, and computers that are organized into trees and forests.
- Apply group policies to manage users and devices.
- Based on LDAP and DNS protocols
- Highly available —> replace manual admin with cloud-based managed service!
-
Architecture
- Sets up a minimum of 2 AD domain controllers which run Windows Server.
- Domain controllers are reachable by applications within your VPC.
- Add additional domain controllers for increased availability and performance.
- Retain exclusive access to the domain controllers.
- Can extend existing AD with AD Trust
-
What is meant by “managed service” in this case?
- AWS
- Multi-AZ deployment.
- Patch, monitor, and recover.
- Instance rotation.
- Snapshot and restore.
- Customer
- Configure users, groups, and group policy objects (GPOs)
- Standard AD tools
- Scaling out domain controllers
- Trusts to build AD forest
- Certificate authorities
- Federation
-
Simple AD: a standalone directory in the cloud that only require simple AD features.
- Small <= 500 users
- Large <= 5000 users
- Easy-to-manage EC2
- Good for Linux workloads that need LDAP.
- Cannot support trusts (cannot be joined to on-premise AD)
-
AD Connector: a directory gateway (proxy) for on-premise AD
- Avoid caching information in the cloud.
- Allow on-premise users to log in to AWS using AD
- join EC2 instances to existing AD domain.
- Can scale across multiple AD Connectors
-
Cloud Directory: directory-based store for developrs to manage hierarchical information
- Not AD compatible
- Multiple hierarchies with hundreds of millions of objects.
- Use cases: org charts, course catalogs, device registries.
- Fully managed service.
-
Cognito User Pools
- Not AD compatible, but still included in Directory Service
AWS Single Sign-On (SSO)
- Managing user permissions within the multi-account strategy
- AWS SSO service helps centrally manage access to AWS accounts and business applications (e.g. MS Office, GitHub, etc).
- Use existing corporate identities is sign on.
- Use case: want to grant security team (1) admin access to accounts running security tools; and (2) auditor access to all other accounts.
-
Security Assertion Markup Language (SAML) 2.0: standard for logging users into applications based on their sessions in another context.
- Example: SSO allows user to log into Slack or G Suite applications using Microsoft AD user context.
- All sign-ons are logged in CloudTrail
Object Storage: Simple Storage Service (S3) and Glacier
Official Resources
General
- One of the first services offered by AWS.
- S3 provides secure, durable, highly scalable object storage.
- Object storage is not suitable for operating system installations. See EBS and EFS instead.
-
Object storage: Object storage (also known as object-based storage) is a computer data storage architecture that manages data as objects, as opposed to other storage architectures like file systems which manage data as a file hierarchy, and block storage which manages data as blocks within sectors and tracks.
- Key: the name of the object.
- Value: the data.
- Version Id: for versioned buckets, a reference to a given version.
- Metadata: such as creation date, tags.
- Access Control Lists: fine-grained controls on storage accesss.
- Files can range from 0 bytes to 5 terabytes.
- Files are stored in buckets. There is no limit on bucket size.
- Universal namespace, so all bucket names must be globally unique.
- The largest object that can be uploaded in a single PUT is 5 gigabytes. For objects larger than 100 megabytes, customers should consider using the Multipart Upload capability.
- When a file is uploaded, if successful then you will receive an HTTP 200 response.
- S3 provides (1) tiered storage; (2) lifecycle management; (3) versioning; and (4) encryption, as additional services.
- Access can be provided at the bucket-level (via Bucket Policies) or object-level (via Access Control Lists).
- S3 Reduced Redundancy Service (RRS): deprecated service similar to S3 One Zone IA.
- While S3 does use availability zones to store objects in buckets, you do not choose the availability zone yourself. Even S3 One Zone-IA does not allow you to specify the AZ for use.
-
Example URLs
- Default:
s3-us-west-2.amazonaws.com/bucketname/path - US East 1: buckets in US East are a special case and should use the special, unique endpoint
s3.amazonaws.com - Static Website:
bucket-name.s3-website-Region.amazonaws.com - Virtual Host:
bucket.s3-aws-region.amazonaws.com
- Default:
- S3 supports two styles of bucket URLs: virtual-hosted-style and path-style URLs. Virtual-hosted-style URLs are of the form
http://bucket.s3-aws-region.amazonaws.com, and path-style URLs are the traditional URLs you’ve seen:https://s3-aws-region.amazonaws.com/bucket-name. - Every S3 object has a key, a value, and a version ID.
Data Consistency Model
- Read-after-write Consistency for PUTs of new objects.
- Eventual Consistency for overwrite PUTs and DELETEs (can take time to propagate).
Service Level Agreement (SLA)
-
Availability —> data is accessible
- S3: four 9’s 99.99%
- S3 IA: three 9’s 99.9%
- S3 One Zone-IA: 99.5%
- Glacier: N/A
- Durability: Eleven 9’s guaranteed —> the data won’t be deleted.
- Take-away: same durability, different availability.
Storage Tiers
S3 Standard
- Four 9’s availability.
- Eleven 9’s durability.
- Stored redundantly multiple devices in multiple facilities, i.e. across different Availability Zones.
- Designed to withstand the loss of 2 facilities concurrently.
- Highest cost
S3 Infrequently Accessed (S3 IA)
- Designed for data that is infrequently accessed, but requires rapid access when needed.
-
Lower base fee than S3, but charged for data retrieval.
- S3-IA charges all objects as if they are at least 128 KB in size. So while you can store a smaller object in S3-IA, it will be considered 128 KB for pricing and charging purposes.
- Same redundancies as S3 Standard.
S3 One Zone IA
- Designed for users who want an even lower cost than S3 IA and who do not require the same level of data resiliency.
- It’s more or less all in the name.
S3 Intelligent Tiering
- Designed to optimize costs by automatically moving data to the most cost-effective access tier, without performacne impact or operational overhead.
S3 Glacier
- S3 Glacier is a secure, durable and low-cost storage class for data archiving.
- Reliably store any amount of data.
- Retrieval times are configurable from minutes to hours.
S3 Glacier Deep Archive
- Lowest-costs storage class where a retrieval time of 12 hours is acceptable.
Pricing Tiers
-
Types of Charges
- Storage (amount of space)
- Requests (how many times an object is accessed)
- Storage Management (object tags, etc)
- Data Transfer (e.g. cross region replication)
- Transfer Acceleration (a service that uses AWS CloudFront edge locations to dramatically speed up file transfer rates).
- Cross-region replication.
-
Storage
- Standard
- IA: about half of standard
- Intelligent Tiering: same as standard, but sometimes can be reduced to IA pricing. But also incurs monitoring and automation costs (per 1000 objects)
- One Zone IA: slightly less that IA
- If zone fails, your data is toast.
- Glacier: fractional costs
- Glacier Deep Archive: fraction of fractional costs
-
How to get the best value
- Best value is Intelligent Tiering unless you have high volume of objects.
Versioning
- From the FAQ: Versioning allows you to preserve, retrieve, and restore every version of every object stored in an Amazon S3 bucket. Once you enable Versioning for a bucket, Amazon S3 preserves existing objects anytime you perform a PUT, POST, COPY, or DELETE operation on them. By default, GET requests will retrieve the most recently written version. Older versions of an overwritten or deleted object can be retrieved by specifying a version in the request.
- Not enabled by default.
- Once enabled, cannot be disabled; only suspended.
- Once enabled, stores all versions of an object (includes all writes, including deletes).
- Integrates with Lifecycle Management, e.g.
- Deletes are denoted by a delete flag.
- Each object in S3 has a name, value (data), version ID, and metadata. The version history of an object won’t exist unless versioning is turned on.
MFA Delete
- MFA Delete applies to deleting objects, not buckets. It affects changing the versioning state of a bucket or permanently deleting any object (or a version of that object).
- Only the root account can enable MFA Delete. Even the console user that created the bucket—if it isn’t the root user—cannot enable MFA Delete on a bucket.
Cross Region Replication
- Versioning must be enabled on both source and destination buckets.
- Regions must be different (obviously).
- Existing files in source bucket are not replicated automatically; however, all subsequent updates are replicated automatically.
- Can use CLI to manually copy existing files in source bucket.
- Cannot replicate to multiple destination buckets or daisy chain (at this time).
- Delete markers are not replicated.
- Deletion of individual versions or delete markers are not replicated.
Lifecycle Management
- Use case: at set time intervals, move a file from S3 to S3 IA to Glacier, as the file’s immediacy changes.
- Versioning is not required, but can be used.
- Can transition from S3 to S3 IA after a minimum of 30 days.
- Can transition from S3 IA to Glacier after a minimum of 30 days (or net 60 days from S3 —> S3 IA —> Glacier).
- Can use Lifecycle Management to permanently delete objects.
Security and Encryption
- By default, all new buckets are private. Therefore, cannot access publicly.
-
Security Levels
- Bucket Policy: bucket-level permissions.
- Access Control Lists: object-level permissions.
- S3 buckets can be configured to create access logs, which log all requests made to the bucket. The logs can be sent to a destination bucket and this destination bucket can reside in another account.
-
Encryption Types
- In Transit using HTTPS SSL/TLS.
- At Rest Server Side Encryption (SSE): (1) S3 Managed Keys; (2) KMS Managed Keys; and (3) customer provided keys.
- S3 Managed Keys (SSE-S3): every object gets as unique key, and the key itself encrypted.
- Key Management Service (SSE-KMS): Separate permissions for envelop key. Provides audit trail for key usage and by whom.
- Customer Provided Keys (SSE-C): Customer can use their own key(s).
- At Rest Client Side Encryption: data is encrypted on client and then uploaded to S3.
Performance
-
Prefix: the path between bucket name and object name.
- Can achieve 3,500 PUT/COPY/POST/DELETE and 5,500 GET/HEAD requests per second per prefix.
- Improve performance by spreading ops across different prefixes.
-
Limitations when using KMS
- When uploading a file, must call GenerateDataKey in the KMS API.
- When downloading a file, must call Decrypt in the KMS API.
- Uploads and downloads count towards KMS quota. (hard limit; cannot request a quota increase)
-
Multi-part Uploads: parallelize uploads
- Recommended for files over 100 MB
- Required for files over 5 GB
-
Byte-Range Fetches: parallelize downloads by specifying byte ranges.
- If failure occurs, it is only for specific byte range.
S3 Object Lock & Glacier Vault Lock
-
S3 Object Lock: Store objects using a write once, read many (WORM) model. It can help prevent objects from being deleted or modified for a fixed amount of time (or indefinitely).
- Meet regulations that require WORM storage.
- Add extra layer of protection against object change or deletion.
- Can be applied on individual objects or across the bucket as a whole.
- Governance Mode: users cannot overwrite or delete an object version or alter its lock settings except with special permission.
- Compliance Mode: a protected object version cannot be overwritten or deleted by any user, including the root user. Retention mode cannot be changed and retention period cannot be shortened.
- Legal Hold: no retention peiod, just remains in effect until removed. Prevents object modfication or deletion.
- Glacier Vault Lock: Deploy and enforce compliance controls for individual S3 Glacier vaults with a Vault Lock policy. Specify controls, such as WORM, in a Vault Lock policy and lock the policy from future edits. Once locked, policy cannot be changed.
S3 Select & Glacier Select
- Enables applications to retrieve only a subset of data from an object by using simple SQL expressions.
- Improves application performance by off-loading data querying and filtering from application to S3 Select. Only downloads the data you need.
- Glacier Select is similar: some highly regulated industries - such as financial services or healthcare - write data directly to Glacier to satisfy compliance needs like SEC Rule 17a-4 or HIPAA. Glacier Select allows user to run SQL queries directly against Glacier data.
AWS Organizations & Consolitated Billing
- An account management service that enables user to consolidate multiple AWS accounts into a single organization that can be centrally managed.
- Best Practice: User root account for billing only.
- Apply service control policies to organizational units or single account (i.e. don’t let accountants spin up EC2s).
- AWS resources decrease in marginal cost at higher usage. AWS Organizations aggregates usage, and so user can get to cheaper tiers faster.
- Makes it easy to track charges and allocate costs.
Athena & Macie
-
Athena is an interactive query service which enables you to analyze and query data located in S3 using standard SQL.
- Athena is serverless, there is nothing to provision.
- Pricing: Pay per query per TB scanned.
- No need to setup ETL processes.
- Works directly with data stored in S3.
- Use cases: query access logs, generated business reports, analyze cost and use reports, run queries on clickstream data.
- Athena vs S3 Select (from StackOverflow):
- AWS S3 Select is a cost-efficient storage optimization that allows retrieving data.
- AWS Athena is fully managed analytical service that allows running arbitrary ANSI SQL compliant queries - group by, having, window and geo functions, SQL DDL and DML.
- S3 Select operates on only one object while Athena to run queries across multiple paths, which will include all files within that path.
-
Macie is a security service that uses machine learning and natural language processing (NLP) to discover, classify, and protect sensitive data stored in S3.
- Uses AI to recognize whether an S3 object contains sensitive data, such as Personal Identifiable Information (PII).
- Provides dashboards, reportings and alerts.
- Can also analyze CloudTrail logs.
- Good solution for PCI-DSS and preventing identity theft.
- Athena is active querying; Macie is passive discovery
Other Storage Solutions: Storage Gateway and Snowball
Official Resources
General - Storage Gateway
- Storage Gateway is a virtual machine image that can be installed on a host in your data center. Once installed and associated with an AWS account, the gateway can be configured and provides a direct line into AWS.
- The Storage Gateway service is primarily used for attaching infrastructure located in a Data centre or office to the AWS Storage infrastructure. The AWS documentation states that; “You can think of a file gateway as a file system mount on S3.”
- AWS storage gateway is a virtual appliance that allows on-premises sites to interact with S3 while still caching (in certain configurations) data locally.
- AWS storage gateway is a virtual appliance and is not available as a hardware appliance.
Storage Gateway Types
- Gateway types are File or Volume
-
File Gateway: store flat files in S3.
- File Gateway enables you to store and retrieve objects in Amazon S3 using file protocols, such as Network File System (NFS). Objects written through File Gateway can be directly accessed in S3.
- Use cases for File Gateway include:
- (a) migrating on-premises file data to Amazon S3, while maintaining fast local access to recently accessed data
- (b) Backing up on-premises file data as objects in Amazon S3 (including Microsoft SQL Server and Oracle databases and logs), with the ability to use S3 capabilities such as lifecycle management, versioning and cross region replication
- (c) Hybrid cloud workflows using data generated by on-premises applications for processing by AWS services such as machine learning, big data analytics or serverless functions.
- File Gateway volumes retain a copy of frequently accessed data subsets locally.
-
Volumes Gateway (iSCSI): The volume gateway provides block storage to your applications using the iSCSI protocol. Data on the volumes is stored in Amazon S3. To access your iSCSI volumes in AWS, you can take EBS snapshots which can be used to create EBS volumes. The snapshots capture the incremental changes to save space.
- Stored Volumes: store files on premise, back up to AWS.
- All data is backed up to S3 asynchronously when a stored volume is used. This ensures that no lag is incurred by clients that interact with the stored volumes on-site.
- Cached Volumes: only store recently accessed data on premise, back up everything else to AWS. Helps minimize the need to scale at the local data center, while still providing low latency to frequently accessed data.
- Tape Gateway (VTL): The tape gateway provides your backup application with an iSCSI virtual tape library (VTL) interface, consisting of a virtual media changer, virtual tape drives, and virtual tapes. Virtual tape data is stored in Amazon S3 or can be archived to Amazon Glacier.
General - Snowball
- Formerly known as Import/Export Disk
- Essentially a standard piece of storage hardware for manually delivering (potentially) huge amounts of data directly into (and out of) AWS. Bypass the internet tubes!
- In their own words: AWS Snowball is a data transport solution that accelerates moving terabytes to petabytes of data into and out of AWS using storage devices designed to be secure for physical transport. Using Snowball helps to eliminate challenges that can be encountered with large-scale data transfers including high network costs, long transfer times, and security concerns.
-
Snowball Types
- Snowball
- Snowball Edge: the same as Snowball, but with compute capability. Basically a mini AWS, so you can bring compute capacity to places where it does not typically exist. E.g., you can run a lambda from a Snowball Edge.
- Snowmobile: it’s a truck.
Content Delivery Network (CDN): CloudFront
Official Resources
General
- A CDN is a system of distributed servers that deliver content to a user based on geographic locations of (1) the user; (2) the origin of the content; and (3) the content delivery server.
-
Edge Location: The location where the content is cached. Edge Locations are different than Regions and Availibility Zones.
- Edge Locations support both read and write operations. If write, then changes are replicated back to Origin.
- Origin: The origin of all the files that the CDN will distribute, e.g. an S3 bucket, an EC2 instance, an ELB, or Route53.
-
Distribution: The name of your CDN.
- CloudFront supports both web distributions and RTMP distributions.
- An RTMP distribution is the Adobe Real-Time Messaging Protocol and is suitable for using S3 buckets as an origin server to serve streaming media.
- Objects are cached for the Time To Live (TTL).
- Cache can be manually cleared (an “invalidation”) for a charge.
- CloudFront is intended to cache and deliver static files from your origin servers to users or clients. Dynamic content is also servable through CloudFront from EC2 or other web servers.
- CloudFront serves content from origin servers, usually static files and dynamic responses. These origin servers are often S3 buckets for static content and EC2 instances for dynamic content.
- CloudFront is able to distribute content from an ELB, rather than directly interfacing with S3, and can do the same with a Route 53 recordset. These allow the content to come from multiple instances.
- Edge locations allow objects to be written directly to them.
- Default TTL for edge locations is 24 hours.
- When you create a CloudFront distribution, you register a domain name for your static and dynamic content. This domain should then be used by clients.
- There is no charge associated with data moving from any region to a CloudFront edge location.
- The invalidation API is the fastest way to remove a file or object, although it will typically incur additional cost.
Distribution Types
- Web Distribution: for distributing websites, derrrrrr.
- Real-Time Messaging Protocol (RTMP): for media streaming.
Signed URLs and Cookies
- Want to restrict content access to certain users?
-
Use cases
- Signed URLs: single file access
- Cookie: multiple files access
-
For either, attach a policy. Policy can include…
- Expiration
- Allowed IP ranges
- Trusted signers (i.e. which AWS accounts can create signed URLs)
- User cannot access origin, but can access CDN which can itself access origin.
- Application can use AWS SDK to generate signed URL or Cookie and return it to the client. Client can then use CDN to access origin (or cache).
-
S3 can also provide S3 Signed URLs
- Presigned URL provides ability to request as the IAM user who generated the presigned URL. These credentials are associated with the URL but are not encrypted into the URL itself.
- Presigned URLs are not tied to specific AWS services. They are simply URLs that can point at anything a normal URL can point at, except that the creator can associate permissions and a timeout with the URL.
- A presigned URL is always configured at creation for a valid Time to Live (often referred to as TTL). This time can be very short, or quite long.
Elastic Compute Cloud (EC2)
Official Resources
General
- EC2 is a web service that provides resizable compute capacity in the cloud. EC2 = speed in provisioning or eliminating compute capacity.
-
Purchase and Pricing Options
- On Demand: pay fixed rate by the hour with no commitment.
- Reserved: provides reserved capacity in 1- or 3-years terms for significantly reduced costs.
- Spot: bid for capacity; no guarantees.
- If spot instance is terminated by AWS, no charge to consumer for partial hour.
- However, if consumer terminates instance with partial hour, consumer is charged.
- Dedicated Hosts: dedicated physical EC2 server.
- Can only toggle between Dedicated mode and Host mode; cannot be changed from or to Default mode (shared tenancy)
- Assign an IAM Role (i.e. limit permitted actions) to an EC2 in order to lock down blast radius from security breach.
-
Metadata about an instance is available; can get info about an instance (such as its public ip or the user data script).
- TODO: Certificates are related to SSL and help define the identity of a site or transmission.
- TODO: pricing; fefects of reboots
Instance Types
- Mnemonic: “Fight Dr McPx”
- F - Field Programmable Gate Array: financial analytics, big data, real-time video processing.
- I - IOPS: high-speed storage, e.g. NoSQL DBs, data warehousing.
- G - Graphics: for video encoding, 3D application streaming.
- H - High Disk Throughput:
- T - t???: Cheap general purpose, e.g. T2 Micro
- D - Density: dense storage, e.g. fileservers, data warehousing
- R - RAM: for memory-intensive apps
- M - Main: general purpose applications.
- C - Compute: for CPU-intensive apps.
- P - general Purpose gpu: e.g. machine learning, bitcoin mining
- X - eXtreme Memory: memory optimized, e.g. SAP HANA or Apache Spark
Security Groups
- Security Groups operate at the instance level, they support “allow” rules only, and they evaluate all rules before deciding whether to allow traffic.
-
Default security group settings
- All Inbound Traffic is blocked by default.
- All Outbound Traffic is allowed by default.
- Instances in group can talk to one another.
- Changes to Security Groups take effect immediately.
- A Security Group can contain any number of EC2 instances.
- Multiple Security Groups can be attached to an EC2 instance.
- Security Groups are stateful: if an inbound rule allows traffic in, then that traffic (response) is allowed back out again.
- Security Group cannot block a specific IP address; to do so, use Network Access Control Lists.
- Security Groups whitelist. Network Access Control Lists blacklist.
Amazon Machine Images (AMIs)
- An AMI provides the information required to launch an instance, which is a virtual server in the cloud. You must specify a source AMI when you launch an instance.
- AMI selection criteria include: (1) Region; (2) operating system; (3) architecture (e.g. 32-bit or 64-bit); (4) launch permissions; (5) root device storage / volume (e.g. instance store or EBS).
- AWS does not automatically copy launch permissions, user-defined tags, or S3 bucket permissions for an AMI across regions.
- All AMIs are caterogized as backed by either (1) EBS; or (2) instance store.
-
EBS-backed
- The root device store is an EBS volume created from an EBS snapshot.
- EBS stores can be stopped. No data is lost on stop and start.
- No data loss on reboot.
- By default, root volume is deleted on instance termination; however, root device volume protection can be toggled on.
-
Instance store-backed
- The root device store is an instance store volume created from a template stored in S3.
- Instance stores cannot be stopped; if the underlying host fails, then the data is lost.
- No data loss on reboot.
- No means to preserve on instance termination.
- Use case: An instance store provides temporary block-level storage for your instance. This storage is located on disks that are physically attached to the host computer. Instance store is ideal for temporary storage of information that changes frequently, such as buffers, caches, scratch data, and other temporary content, or for data that is replicated across a fleet of instances, such as a load-balanced pool of web servers.
- AMI can be created from a running instance ONLY if “no reboot” option is selected.
ENI vs ENA vs EFA
-
ENI (Elastic Network Interface): a virtual network card.
- All EC2s include one ENI; can optionally add additional ones.
- Use Cases for multiple ENIs:
- Create a management network separate from test or prod networks.
- Use network and security appliances in the VPC.
- Create dual-homed instances with workloads/roles on distinct subnets.
- Create a low-budget, high-availability solution.
-
EN (enhanced networking): uses a single root I/O virtualization to provide high-performance networking capabilities on supported instance types. For when ENIs are not capable of the necessary throughput.
- Uses single root I/O virtualizatoin (SR-IOV) to provide high-performance networking capabilities on supported instance types. SR-IOV is a method of device virtualization that provides higher I/O performance and lower CPU utilization when compared to traditional virtualized network interfaces.
- EN provides higher bandwidth, higher packet per second (PPS) performance and consistently lower inter-instance latencies. There is no additional charge for using EN, but instance type must support it.
- ENA (Adapter): supports network speeds of up to 100 Gbps
- Virtual Function (VF) interface: supports network speeds of up to 10 Gbps; typically for older instance types that don’t support ENA.
- Tips
- If an instance supports both, pick ENA over VF.
- ENA vs ENI: if question about supporting network speed, pick ENA. Adding more ENIs does not necessarily increase throughput.
-
EFA (Elastic Fabric Adapter): a network device that can attach to an EC2 instance to accelerate High Performance Computing (HPC) and machine learning applications.
- Provides lower and more consistent latency and higher throughput than the TCP transport traditionally used in cloud-based HPC systems.
- Can use OS-bypass, which enables HPC and machine learning applications to bypass the operating system kernel and to communicate directly with the EFA device. Dramatically increases speed and decreases latency. Only supported by Linux.
Spot Instances & Spot Fleets
- Take advantage of unused EC2 capacity at up to 90% discount compared to On-Demand pricing.
-
Use cases: stateless, fault-tolerant, or flexible applications such as big data, containerized workloads, CI/CD, web-servers, HPC, image and media rendering, and other test and development workloads.
- Not good for: persistent workloads, critical jobs, databases.
- Decide your maximum spot price; instance is provisioned provided that the spot price is below your maximum. If price goes over, you have 2 minutes to decide whether or not to terminate.
- Spot block: stops a spot instance from being terminated when price exceeds preset maximum. Can be set for between 1 and 6 hours.
-
Spot Instance Termination: depends on your “Request Type”, one-time or persistent.
- If one-time, dies and doesn’t come back.
- If persistent, is disabled and will go back to an open request and would be relaunched if spot price dips below maximum again.
-
Spot Fleet: a collection of spot and on-demand instances.
- Attempts to launch instances of both types to meet target capacity.
- Prefers spot instances, but tops up with on-demand instances.
- Launch Pools: defines things like EC2 instance type, OS, AZ, etc.
- Strategies
- Capacity Optimized: spot instances come from the pool with optimal capacity for the number of instances launching.
-
Lowest Price: spot instances come from the pool with the lowest price. (Default)
- InstancePoolstoUseCount: spot instances are distributed across the number of spot instance pools you specify. This parameter is valid only when used with Lowest Price.
- Diversified: spot instances are distributed across all pools.
- TODO: minimum cost
EC2 Hibernate
- Reminder: when an instance is stopped, data remains on the associated EBS volume. When an instance is terminated, the volume is also terminated and data is lost.
-
When an EC2 instance is started…
- Operating system boots up.
- Use data script is run. (bootstrap script)
- Application(s) start.
- When an EC2 instance is hibernated, the operating system is told to perform hibernation (suspend-to-disk). Hibernation saves the contents from the instance memory (RAM) to EBS root volume.
-
When an instance is restarted out of hibernation…
- EBS root volume is restored to its previous state.
- RAM contents are reloaded.
- The processes previously running on the instance are resumed.
- Previously attached data volumes are reattached and instance retains its instance ID.
- Use cases: long-running processes or services that take a long time to initialize.
- Note: Instance RAM must be less than 150 GB.
- Cannot hibernate for more than 60 days.
Placement Groups
-
You can launch or start instances in a placement group, which determines how instances are placed on underlying hardware.
- Permitted instance types: (1) compute optimized; (2) GPU; (3) memory optimized; (4) storage optimized.
-
Cluster: clusters instances into a low-latency group in a single Availability Zone. Recommended for applications that require low network latency, high network throughput, or both.
- CANNOT span multiple AZs.
-
Spread: spreads instances across underlying hardware. Recommended for applications that have a small number of critical instances that should be kept separate from one another.
- Maximum of 7 running instances per AZ.
- Partition: spreads instances across logical partitions, ensuring that instances in one partition do not share underlying hardware with instances in other partitions.
- AWS recommends that placement groups contain homogeneous instances (same size and same instance type family).
- Placement groups cannot be merged.
- Cannot move an existing instance into a placement group. Work-around: Create an AMI from the existing instance, then launch a new instance from the AMI into the placement group.
Elastic Block Storage
Official Resources
General
- EBS is used to create storage volumes and attach them to an EC2 instance. Once attached, you can (1) create a file system on top of the volume, (2) run a database, or (3) use it in any way you would use a normal block device.
- EBS volumes live in a specific AZ but are automatically replicated to protect against single component failure.
- Can only attach one EBS per EC2 instance (not shareable).
Volume Types
- General Purpose SSD (GP2): balances price and performance.
-
Provisioned IOPS SSD (IO1): designed for I/O intensive applications, such as large relational or NoSQL databases.
- Use if you need more than 10,000 IOPS.
- Can provision up to 20,000 IOPS.
- Throughput Optimized HDD (ST1): designed for big data, data warehouses, log processing. Cannot be a boot volume.
- Cold HDD, aka Magnetic: designed for workloads where data is accessed infrequently and applications where the lowest storage cost is important.
Snapshots
-
A snapshot is a static copy of an EBS volume.
- If you make periodic snapshots of a volume, the snapshots are incremental which means only the blocks on the device that have changed after your last snapshot are saved in the new snapshot.
- Even though snapshots are saved incrementally, the snapshot deletion process is designed such that you need to retain only the most recent snapshot in order to restore the volume.
- In order to snapshot a root device EBS volume, best practice is to stop the instance first. However, a snapshot can be taken from a running instance.
- Users can create AMI’s from EBS-backed instances and snapshots.
- Users can change EBS volumes on the fly, including both size and storage type.
- An EBS volume is always in the same AZ as its attached EC2; in order to move it to another AZ or Region, take a snapshot and copy it to the new AZ or Region.
- Snapshots of encrypted volumes are encrypted automatically.
- Volumes restored from encrypted snapshots are encrypted automatically.
- Only unencrypted snapshots can be shared; can be shared with other AWS accounts or made public.
RAID on Windows EC2
-
RAID = Redundant Array of Independent Disks
- RAID 0: disks are striped. Good for performance but no redundancy.
- RAID 1: disks are mirrored. Complete redundancy, no performance gains.
- RAID 5: 3 disks or more and writing parity. Good for reads, bad for writes. RAID 5 is never the recommended solution.
- RAID 10: disks are striped and mirrored. Good performance and good redundancy.
- RAID is used when you need higher I/O (usually go with 0 or 10).
-
RAID Snapshots
- Problem: the full snapshot is actually spread across several volumes. Some data is held in cache.
- Solution: take an “application consistent snapshot.” Stop the application from writing to disk and flush all caches to disk. Options: (1) Freeze the file system; (2) unmount the RAID array; or (3) shut down the associated EC2 instance.
Elastic File System
Official Resources
General
- EFS is a fully-managed service that automatically scales file storage in the Amazon Cloud.
- Storage that can be shared between resources, such as EC2s (unlike EBS).
- Supports Network File System Version 4 (NFSv4) protocol.
- Pricing: only pay for what you use; no pre-provisioning (in contrast to EBS).
- Scales up to petabytes.
- Supports thousands of concurrent NFS connections.
- Data is stored across multiple AZs within a region.
- Read after write consistency.
- Use case: file server; centralized repository use by mutliple EC2s. Can apply user- and directory-level permissions to be universal across EC2 instances.
EFS vs Windows FSx
-
Windows FSx
- A managed Windows Server that runs Windows Server Message Block (SMB) -based file services.
- Designed for Windows and Windows applications.
- Supports AD users, access control lists, group and securuty policies, and Distributed File System (DFS) namespaces and replication.
-
EFS
- A managed NAS filer for EC2 instances based on Network File System (NFS) version 4.
- One of the first netowrk file sharing protocols native to Unix and Linux.
- FSx for Lustre: optimized for compute-instensive (i.e. HPC) workloads.
Elastic Load Balancers (ELB)
Official Resources
General
- A physical or virtual device that balances load across multiple servers.
-
Two main components: the load balancers and the controller service.
- The load balancers monitor the traffic and handle requests that come in through the Internet.
- The controller service monitors the load balancers, adding and removing load balancers as needed and verifying that the load balancers are functioning properly.
- Three types: (1) Application (ALB); (2) Network (NLB); (3) Classic (CLB)
-
Application: best suited for load balancing HTTP and HTTPS traffic. ALBs operate at Layer 7 (application layer) and are application-aware. ALBs can have advanced request routing that sends specified requests to specific web servers.
- Load balancer could be user-preference aware to change e.g. language or currency.
- Capable of advanced routing.
- ALBs are redundant across at least two subnets.
- Network: best suited for load balancing TCP traffic where extreme performance is required. NLBs operate at Layer 4 (network layer). NLBs are capable of handling millions of requests per second while maintaining ultra-low latencies.
- Classic: legacy ELBs. Classics can load balance HTTP and HTTPS with Layer 7-specific features or can load balance on TCP with Layer 4-specific features. Not recommended anymore.
- 504 Errors: Gateway Timed Out because the underlying application stops or fails. Could be web server or database, not the load balancer itself. Might need to scale up or out.
- X-Forwarded-For: A load balancer forwards requests, but from the ELB’s private IP. If you need the IPv4 address of an end user, look at the X-Forwarded-For header.
- Healthchecks: generally a simple ping to see if a 200-level response is received. Instances monitored by an ELB are either InService or OutofService.
- CLBs and ALBs only provide DNS name, never an IP address. By contrast you can get a static IP for an NLB.
- No cross-region load balancing
Advanced Load Balancer Theory
-
Sticky Sessions: a Classic Load Balancer sticky session allows you to bind a user’s sessions to a specific EC2 instance.
- This ensures that all requests from the user during the session are sent to the same instance.
- This feature is useful if e.g. a user-specific file is saved to the EC2 and must be accessed again by that user.
- It is possible to enable sticky sessions for ALBs, but traffic is routed at the Target Group level (and not the specific EC2 instance level).
- Exam Scenario: given EC2 instances A and B, if sticky sessions is enabled and no traffic is getting to EC2 instance B, then (possibly) disable sticky sessions.
-
Cross-Zone Load Balancing: load balancer within an Availability Zone is able to route traffic to instances in other AZs.
- Exam Scenario: AZ 1 has four instances and AZ 2 has one instance. Route53 divides traffic evenly between the AZs. Without Cross-Zone Load Balancing, each AZ 1 instance receives 12.5% of traffic and the AZ 2 instance receives 50% of traffic.
-
Path Patterns: allows you to direct traffic to different EC2 instances based on the URL contained in the request (i.e. path-based routing).
- Scenario: route traffic to multiple backend services from a single host.
Auto Scaling & Auto Scaling Groups (ASGs)
Official Resources
General
-
Three components:
- Groups: the logical component, i.e. Webserver group, Application group, or Database group, etc.
- Configuration Templates: Groups use a launch template or a launch configuration as the configuration template for its EC2 instances. Can specify information such as AMI id, instance type, key pair, security groups, and block device mapping for instances.
- Launch configurations are concerned primarily with creating new instances while staying abstract from the details of what is on those instances.
- Scaling Options: ways to scale the ASG, such as based upon occurrence of conditions or as scheduled.
-
Scaling Options
- Maintain: periodic healthchecks ensure that specified configuration is maintained at all times. When an unhealthy instance is found, ASG terminates it and launches a new one.
- Scale Manually: Specify only the maximum, minimum, and desired capacity. ASG handles creation and termination of instances to maintain manually indicated capacity.
- Scale on Schedule: scaling actions performed automatically as a function of date and time. Useful when you have predictable scaling needs, such as SOD or EOD.
- Scale on Demand (dynamic/reactive): define scaling policies to execute scaling actions when certain conditions are met. For example, if CPU utilization reaches 50% for 1 hour, then add additional EC2 instance.
- Predictive Scaling: AWS Auto Scaling (separate resource? Yes!) helps you maintain optimal availability and performance by combining predictive scaling and dynamic scaling (proactive and reactive approaches, respectively) to scale EC2 capacity faster.
Highly Available (HA) Architecture
General
- Plan for failure. Resources (DBs, instances) can go down. Availability Zones can go down. Regions can go down.
- Use multiple AZs and multiple Regions.
- Multiple AZ is for disaster recovery. Read Replicas (RDS) is for performance.
- Scaling out (use ASG to add more instances) vs scaling up (more resources within an instance).
- S3 and S3-IA are highly available.
- Availability Zone names are unique per account and do not represent a specific set of physical resources.
Bastions
- A bastion is a special purpose server instance that is designed to be the primary access point from the Internet and acts as a proxy to your other EC2 instances.
- Solves the problem of proliferating access points to your system as the number of EC2 instances grows.
-
Make a bastion highly available by putting one bastion in each AZ, then put both behind a NLB (which would share traffic between the two bastions).
- NOTE: NLBs are expensive, so this strategy is best for Prod.
-
For a development environment, can get away with an ASG (instead of an NLB) and default to one bastion. If it goes down, ASG can spin up a new bastion in a different AZ.
- Drawback is that there will be downtime between bastion 1 going down and the ASG spinning up bastion 2.
On-Premise Strategies
-
Database Migration Service (DMS)
- Allows you to move databases to and from AWS cloud.
- Use case: local DB is primary and AWS cloud DB is the Disaster Recovery (DR) environment.
- Works with most popular DB types (Oracle, MySQL, etc)
- Supports homogenous migration (Oracle -> Oracle) and heterogenous migration (MySQL -> Aurora)
-
Server Migration Service (SMS)
- Supports incremental replication of on-premise servers to AWS.
- Use cases: backup tool, multi-site strategy, and Disaster Recovery.
-
AWS Application Discovery Service
- This service helps enterprise customers plan migration projects by gathering information about the on-premise data centers.
- Install AWS Application Discover Agentless Connector as a virtual application on VMware vCenter.
- The Agentless Connector builds a server utilization map and dependency map of the on-premise environment.
- The collected data is encrypted and retained. Data can be exported as CSV and used to estimate Total Cost of Ownership (TCO) of running on AWS and to plan migration to AWS.
- Same data is available on AWS Migration Hub, which helps migrate discovered servers and track the migration progress.
-
VM Import/Export
- Migrate existing applications to EC2.
- Create a Disaster Recovery strategy on AWS or use AWS as a second site.
- Can export AWS VMs back to on-premise.
-
Download Amazon Linux 2 as an ISO
- Essentially run an EC2 locally.
High Performance Compute (HPC)
- HPC can be achieved on AWS by designing infrastructure to optimize for data transfer, compute and networking, storage, and orchestration and automation.
-
Data transfer
- Use snowball or snowmobile (terabytes/petabytes of data).
- AWS Datasync to store on S3, EFS, FSx for Windows, etc.
- Direct Connect (dedicated line into AWS data center)
-
Compute and Networking
- EC2 instances that are GPU or CPU optimized.
- EC2 fleets (spot instances or spot fleets).
- Placement groups.
- Enhanced networking single root I/O virtualization (SR-IOV).
- Elastic Network Adapters (or Intel 82599 Virtual Function (VF) interface)
- Elastic Fabric Adapters.
-
Storage
- Instance-attached storage, such as EBS, Instance Store
- Network storage: S3 or EFS or FSx for Lustre
-
Orchestration and Automation
- AWS Batch
- AWS ParallelCluster
AWS WAF (web application firewall)
- AWS WAF is a web application firewall that monitors the HTTP and HTTPS requests that are forwarded to CloudFront, an ALB, or API Gateway. Let’s you control access to your content.
- Is Layer 7-aware
- Can filter on IPs or query strings
-
Possible behaviors
- Allow all except as filtered.
- Deny all except as filtered.
- Count the requests that match specified properties.
-
Get protection based on web request conditions…
- IP addresses (or ranges)
- Country of origin
- Request header values
- Strings, either specific values or regex patterns
- Length of requests
- Presence of SQL code that is likely to be malicious (i.e. SQL injection)
- Presence of a script that is likely to be malicious (i.e. cross-site scripting)
Elastic Beanstalk
- Infrastructure for people who don’t like infrastructure.
- For users who want to provision preset infrastructure without having to understand the complexity of the underlying resources. EBS handles capacity provisioning, load balancing, scaling, and application health monitoring.
Application Resources
SQS
-
A managed queue service.
- Pull-based resource; some active component needs to pull messages off of the queue.
- Retention TTL range is 1 minute to 14 days. Default is 4 days.
- Helps decouple infrastructure. The queue acts as a buffer between the component producing and saving data and the component receiving the data for processing.
- Use case: If an EC2 processing a message fails, then the message can return to the queue and be taken up by the next available EC2.
- Default message max size in 256 kb; if you need more, the message must be stored in S3.
- Resolves issues that arise between a producer that can operate faster than a consumer.
-
Standard Queues
- Nearly unlimited transactions per second.
- At-least-once delivery guaranteed, but may receive duplicate message.
- Delivery order not guaranteed. Only best-effort ordering.
-
FIFO Queue
- Guaranteed delivery order.
- Guaranteed exactly-once processing.
- Limited to 300 transactions / sec.
-
Visiblity Timeout is the amount of time that a message is invisible but still in the queue after a reader pulls the message.
- If the reader job is processed before the visibility timeout expires, then the message is deleted from the queue.
- If the reader job is not processed before the visibility timeout expires, then the message is remade visible in the queue and will be pulled again. This could result in the same message delivered twice.
- Timeout maximum is 12 hours.
-
Short vs Long Polling
- With short polling, the
ReceiveMessagerequest queries only a subset of the servers (based on a weighted random distribution) to find messages that are available to include in the response. Amazon SQS sends the response right away, even if the query found no messages. - With long polling, the
ReceiveMessagerequest queries all of the servers for messages. Amazon SQS sends a response after it collects at least one available message, up to the maximum number of messages specified in the request. Amazon SQS sends an empty response only if the polling wait time expires.
- With short polling, the
Simple Workflow Service (SWF)
- A web service that makes it easy to coordinate work across distributed application components. Enables a range of use cases, such as media processing, web application backends, business process workflows, and analytic pipelines. These can be designed and defined as a coordination of tasks.
- A Task represents invocations of various processing steps in an application, which can be performed by executable code, web service calls, human actions, and scripts.
- O2O workflows >_< exam scenario is Amazon warehouses where digital transactions (order creation) combines with offline transactions (employee delivers a product).
- Max length is 1 year.
- Task-oriented API (vs message-oriented API for SQS).
- No duplication.
- Tracks all tasks and events within an application (vs need to implement application-level tracking with SQS).
-
SWF Actors
- Workflow Starters: events that kick off a workflow
- Deciders: controls flow of activity tasks
- Activity Workers: compute for tasks
- SWF provides an API, but it is neither the AWS-specific API nor language specific. Instead, SWF supports standard HTTP requests and responses.
- SWF is typically thought of as an asynchronous service, but it also supports synchronous tasking when needed.
- SWF is associated with tasks and is distinct from (for example) SQS, because it guarantees a single delivery of all tasks.
- SWF tasks are assigned once and only once.
- A SWF domain is a collection of related workflows.
SNS
- Managed service that provides highly scalable capability to publish messages from an application to subscribers.
- Use cases: push notifications to SMS, email, SQS, or any HTTP endpoint.
- Topic: an easy way to group subscribers and deliver identical copies of the same notification.
- All messages are stored redundantly across multiple AZs.
-
Benefits
- Instantaneous push-based delivery.
- Simple APIs make for easy integrations.
- Multiple transport protocols.
- Pay-as-you-go model and no upfront costs.
Elastic Transcoder
- Media transcoder accessible as an API.
- Convert media files from their original source format into different formats, such as to deliver to and play on smartphones, tablets, desktops, etc.
- Provides transcoding presets for popular output formats.
- Pricing: based upon (1) minutes of transcoding; and (2) resolution of transcoding.
API Gateway
- A managed service that makes it easy to publish, maintain, monitor, and secure APIs at any scale.
-
Use cases
- Define a RESTful API and expose HTTPS endpoints.
- Send events to Lambda (or DynamoDB!) via HTTP.
- Use URL paths to connect to different target resources.
- Optionally track and control usage by API key.
- Can throttle requests to prevent attacks.
- Can connect to CloudWatch to log all requests.
- Can maintain multiple versions of an API.
- Cheap and scalable.
- Uses APIG domain by default, but can be aliased to a custom domain (www.example.com).
- Supports SSL/TLS certificates.
-
API caching can be enabled to reduce calls to origin and improve latency.
- Configure response TTL.
-
Includes Same-Origin Policy: a critical security mechanism that restricts how a document or script loaded from one origin can interact with a resource from another origin. Two URLs have the same origin if the protocol, port (if specified), and host are the same for both.
- Critical policy for preventing Cross-Site Scripting (XSS) attacks.
- Cross-Origin Resource Sharing (CORS) allows restricted resources (e.g. fonts) on a web page to be requested from a second domain.
Kinesis
-
Streaming Data: data generated continuously and sent simultaneously by thousands of data sources, typically in small sizes (kb).
- Examples: high volume digital sales, stock prices, real-time game data, geospatial data, IOT data.
- Kinesis makes it easy to load and analyze streaming data.
-
Types
- Streams: data producers stream data to and stored in Kinesis
- Retention period is between 1 and 7 days.
- Data is stored in shards, which can be logical separators (social media shard, IOT shard).
- Consumers can analyze data within the shards.
- Shard: 5 transactions/second for reads, up to read rate of 2 MB/second. Up to 1,000 records/second for writes, up to write rate of 1 MB/second (including partition keys).
- The data capacity of the stream is sum of the capacity of its shards.
- Firehose: no persistence storage, data needs to be operated upon as it comes in.
- Use lambda to provide compute-on-demand.
- Analytics: when paired with Streams or Firehose, can provide analysis on the fly.
Cognito & Web Identity Federation
- Web Identity Federation helps to provide users access to AWS resources after successful authentication with a web-based identity provider, such as Google or Facebook. Following successful authentication, the user receives an authentication code from the Web ID provider, which is then traded for temporary AWS security credentials.
-
Cognito is Web Identity Federation as a service.
- Provides sign-up and sign-in functionalities.
- Can grant guest user access.
- Acts as an Identity Broker (i.e. provides that handy Sign In With Google button).
- Synchronizes user data across devices.
- Temporary credentials map to an IAM role allowing access to required resources. Provides seamless user experience.
- User Pools: for authentication (identity verification). Its a user directory that manages sign-up and sign-in functionality for mobile and web applications.
- Identity Pools: for authorization (access control). Create unique identities for users and give them access to other AWS services.
CloudWatch
Official Resources
General
- Dashboards: monitor AWS resources.
- Alarms: receive alerts when thresholds are hit.
- Events: programmatically respond to state changes in AWS resources.
- Logs: aggregate, monitor, and store logs from AWS resources.
- Using the default settings metrics are sent every 5 minutes to CloudWatch. Using the detailed settings, metrics are then sent every 1 minute.
Domain Name Servers (DNS): Route53
Official Resources
General
- DNS converts a human-readable domain name, such as https://example.com, into an IP address, such as https://12.34.56.78.
- Route53 is named for Port 53, which DNS operates on.
- Start of Authority Record (SOA): stores information about (1) the name of the server that supplied data for the zone; (2) the adminstrator of the zone; (3) the current version of the data file; and (4) the default number of seconds for the TTL file resource records.
- Name Server Record (NS): used by top level domain servers to direct traffic to the content DNS server that contains the authoritative DNS records.
- Address Record (A): used by a computer to translate the name of the domain into an IP address.
- Canonical Name (CNAME): used to resolve one domain to another domain. Redirect visitors from https://mobile.example.com to https://m.example.com.
-
Alias Records: an AWS concept that is used to map resource record sets in your hosted zone to ELBs, CloudFront distributions, or S3 buckets that are configured as websites.
- Alias Records are like AWS-interal CNAMEs in that you map a source DNS name to a target DNS name.
- Material difference: CNAME cannot be used for naked domain names (e.g. https://kwhitejr.com); use Alias or A Records instead.
- Zone Apex: the root domain or naked domain, e.g. kwhitejr.com as opposed to www.kwhitejr.com. The zone apex must be an A Record.
- Time To Live (TTL): the length that a DNS record is cached on either the resolving server or the user’s own computer. TTL is described in seconds. The lower the TTL, the faster changes to DNS records propagate.
- Mail Server Record (MX)
- Reverse Lookups (PTR)
- Route 53 has a security feature that prevents internal DNS from being read by external sources. The work around is to create a EC2 hosted DNS instance that does zone transfers from the internal DNS, and allows itself to be queried by external servers.
Routing Types
- Simple Routing: supports one record with multiple IP addresses. Route53 returns a random value (IP) to the user.
-
Weighted Round Robin (WRR): Weighted Round Robin allows you to assign weights to resource record sets in order to specify the frequency with which different responses are served. You may want to use this capability to do A/B testing, sending a small portion of traffic to a server on which you’ve made a software change. For instance, suppose you have two record sets associated with one DNS name—one with weight 3 and one with weight 1. In this case, 75% of the time Route 53 will return the record set with weight 3 and 25% of the time Route 53 will return the record set with weight 1. Weights can be any number between 0 and 255.
- Weights are simply integers that can be summed to determine an overall weight and the fractional weights of each resource to which traffic is directed.
- A weight of 0 removes the resource from service in a weighted routing policy.
- Weighted policies do honor health checks.
- Latency Based Routing (LBR): Latency Based Routing is a new feature for Amazon Route 53 that helps you improve your application’s performance for a global audience. You can run applications in multiple AWS regions and Amazon Route 53, using dozens of edge locations worldwide, will route end users to the AWS region that provides the lowest latency.
- Failover Routing: used when you want to create an active/passive setup. Route53 monitors the health of the active address and if the healthcheck fails, then traffic is routed to the passive endpoint.
- Geolocation Routing: traffic is routed based upon the geographic location of your end user. Geographic location is based on national boundaries. Use case: EC2s are customized for localities, e.g. with language or currency options.
- GeoPromixity Routing: traffic is routed based upon latitude and longitude.
- Mutlivalue Answer: If you want to route traffic approximately randomly to multiple resources, such as web servers, you can create one multivalue answer record for each resource and, optionally, associate an Amazon Route 53 health check with each record. For example, suppose you manage an HTTP web service with a dozen web servers that each have their own IP address. No one web server could handle all of the traffic, but if you create a dozen multivalue answer records, Amazon Route 53 responds to DNS queries with up to eight healthy records in response to each DNS query. Amazon Route 53 gives different answers to different DNS resolvers. If a web server becomes unavailable after a resolver caches a response, client software can try another IP address in the response.
Databases
Official Resources
Relational Database Service (RDS)
- Supported RDS types: SQL, MySQL, PostgreSQL, Oracle, MariaDB, Aurora
- Ideal for Online Transaction Processing (OLTP): gathering input information, processing the data and updating existing data to reflect the collected and processed information.
- EC2 and RDS may not be able to talk unless their respective security groups are opened to each other.
-
Backups: two flavors, (1) Automated Backups, and (2) Database Snapshots
- Automated Backup: recover database from any point within the retention period (which is 1 to 35 days). Takes a full daily snapshot and also stores transaction logs throughout the day. When a recovery is initiated, AWS chooses the most recent daily back up, then applies the transaction logs from that day. This allows point-in-time recovery down to a second within the retention period.
- Automated Backups are enabled by default. Backup data is stored in S3; user gets free storage equal to the size of the database.
- Elevated latency during backup window (I/O may be suspended); therefore, carefully schedule the backup window.
- By default, Automated Backups are deleted when the RDS instance is deleted.
- DB Snapshots: manual process (user initiated). These are stored even after the RDS instance is deleted.
-
Multi-AZ: When you provision a Multi-AZ DB Instance, Amazon RDS automatically creates a primary DB Instance and synchronously replicates the data to a standby instance in a different Availability Zone (AZ).
- Intended for disaster recovery.
- By pointing to a DNS, rather than an IP, the DB can achieve automatic failover.
- Aurora is Multi-AZ by default.
- Synchronous replication.
-
Read Replicas: create one or more replicas of a given source DB Instance and serve high-volume application read traffic from multiple copies of your data, thereby increasing aggregate read throughput. Read replicas can also be promoted when needed to become standalone DB instances.
- Intended for improved performance.
- Supports up to 5 read replica copies of a DB.
- You can have Read Replicas of Read Replicas, but higher latency.
- Each Read Replica gets its own DNS endpoint.
- Asynchronous replication.
- Can create Read Replicas of Multi-AZ source DBs.
- Read Replica can be in a different region from source.
- Encryption at rest is supported for all RDS flavors. Encryption is through Key Management Service (KMS).
DynamoDB (NoSQL)
- A fast and flexible nonrelational database service for any scale.
- Document and key-value data models.
- Automatically scales throughput capacity to meet workload demands, and partitions and repartitions your data as your table size grows.
- Synchronously replicates data across three facilities in an AWS Region, giving you high availability and data durability.
-
Data consistency models:
- Eventually consistent reads (the default) – The eventual consistency option maximizes your read throughput. However, an eventually consistent read might not reflect the results of a recently completed write. All copies of data usually reach consistency within a second. Repeating a read after a short time should return the updated data.
- Strongly consistent reads — In addition to eventual consistency, DynamoDB also gives you the flexibility and control to request a strongly consistent read if your application, or an element of your application, requires it. A strongly consistent read returns a result that reflects all writes that received a successful response before the read.
-
DynamoDB Accelerator (DAX): full managed, highly available, in-memory cache.
- 10x performance improvement over regular DynamoDB.
- Reduces request time from milliseconds to microseconds, even under load.
- Compatible with DynamoDB API; no application-level logic.
-
Transactions
- Multiple all-or-nothing operations, such as financial transactions (debits and credits must happen simultaneously) or order fulfillment.
- DynamoDB performs two underlying reads or writes of every item in the transaction: one to prepare the transaction and one to commit the transaction.
- Can operate on up to 25 items or 4 MB of data.
- No additional costs, but probably need to up your capacity.
-
On-Demand Capacity
- Pay-per-request pricing.
- Balance cost and performance.
- Autoscales capacity; no minimum.
- No charges when table is idle.
- Costs more per request than provisioned capacity; pricing model is suitable for sporadic or unknown usage.
-
On-Demand Backup and Restore
- Full backups at any time.
- Zero impact on table performance or availability (unlike traditional DBs)
- Consistent within seconds and retained until deleted.
- Operates within same region as the source table.
-
Point-in-Time Recovery (PITR)
- Protects against accidental writes or deletes.
- Restore to any point in the last 35 days.
- DynamoDB automatically takes incremental backups per backup period.
- Not enabled by default; must be manually enabled.
- Latest restorable: Default backup period is 5 minutes.
-
Streams: a time-orderd sequence of item-level changes in a table.
- its like a FIFO queue of data changes (inserts, updates, and deletes).
- Stream records are organized into shards; shards are defined by table partitions.
- Can enable cross-region replication, establish relationships across tables, messages or notifications, analytical reportings, etc.
- Can combine streams with lambda (compute) for functionality similar to stored procedures in relational databases.
-
Global Tables: managed multi-master, multi-region replication
- Enable globally distributed applications.
- Based on streams.
- Get multi-region redundancy for disaster recovery or high availability.
- No application-level awareness required; works out-of-the-box with normal DynamoDB API.
- Replication latency is usually under one second.
-
Database Migration Service
- Facilitates migration from source database (Aurora, S3, MongoDb, etc) to target database.
- Source database remains operational during transfer.
-
Security
- Fully encrypted at rest using KMS
- Can additionally use…
- Site-to-site VPN
- Direct Connect (DX)
- IAM policies and roles
- Fine-grained access with IAM (op-level permissions)
- Can monitor access with CloudWatch and CloudTrail
- Control access with VPC endpoints (and therefore no exposure to public internet)
- HTTP Access: can perform operation via POST, must include headers
host,content-type,x-amz-date,x-amz-target
RedShift
- Ideal for Online Analytical Processing (OLAP): resource intensive and large-scale group, aggregate and join data.
- Primarily used to perform business analytics while not interfering with production resources.
-
Data warehouse cluster options:
- Single Node: enables you to get started with Amazon Redshift quickly and cost-effectively and scale up to a multi-node configuration as your needs grow. A Redshift data warehouse cluster can contain from 1-128 compute nodes, depending on the node type.
- Multi-node: requires a leader node that manages client connections and receives queries, and two compute nodes that store data and perform queries and computations. The leader node is provisioned for you automatically and you are not charged for it.
- Organizes data by columns, which is ideal for data warehousing and analytics, where queries often involve aggregates performed over large data sets. Only the columns involved in the query are processed and columnar data is stored sequentially, column-based systems require fewer I/Os, significantly improving query performance.
- Sequential storage of columnar data permits greater levels of data compression, thus taking less disk space. Additionally, no indexes or materialized views required.
- RedShift samples your data and automatically selects an appropriate compression scheme.
- Massively Parallel Processing (MPP): RedShift automatically distributes data and query load across all nodes. Therefore, adding a node to the data warehouse enables the user to maintain fast query performance as the data warehouse grows.
-
Security
- Encrypted in transit using SSL.
- Encrytped at rest using AES-256.
- Default behavior is RedShift manages keys, but can also use own keys or KMS.
- No Multi-AZ; designed for performance in making reports and queries, not production durability.
Elasticache
- Deploy, operate, and scale an in-memory cache in the cloud. Improves web app performance by retrieving information from fast, managed, in-memory caches, instead of relying entirely on slower disk-based databases.
- Use case: one a t-shirt sales site, splash screen always has Top Ten T-shirts of the week. Instead of hitting the db on every load, use cache.
- Supports two open-source engines: (1) Memcached, and (2) Redis
-
Exam Tips
- Elasticache is useful in scenarios where a particular DB is under a lot of stress/load.
- Elasticache is useful when a database is read heavy and not prone to frequent changing.
- However, RedShift is a better answer if the DB is under stress because management is running OLAP transactions on it.
- ElastiCache uses shards as a grouping mechanism for individual redis nodes. So a single node is part of a shard, which in turn is part of a cluster.
Aurora
- A relational database engine that combines the speed and reliability of high-end commercial databases with the simplicity and cost-effectiveness of open source databases.
- Storage Scaling: start with 10 GB, auto-scale in 10 GB increments to 64 TB.
- Compute Scaling: up to 32vCPUs and 244 GB of memory.
- Resiliency: 2 copies of data per AZ across a minimum of 3 AZs, for a minimum of 6 copies of data.
- Designed to handle loss of up to two copies without affecting write availability and up to three copies without affecting read availability.
- Storage is self-healing: data blocks and disks are continuously scanned for errors and repaired automatically.
-
Can have up to 15 Aurora Read Replicas; user can determine order of priority (tier).
- Up to 5 MySQL read replicas.
- Up to 1 PostgresQL read replica.
- Automatic failover: AWS provides a single cluster endpoint. In case of failure, Aurora automatically changes over to the next tiered instance.
-
Backups
- Automated backups are always enabled. Backups do not impact performance.
- Snapshots are available; also do not impact performance.
- Snapshots can be shared across AWS accounts.
- Aurora Serverless: on-demand, autoscaling configuration of Aurora. Cluster automatically starts up, shuts down, and scales capacity (up or down) based on application needs.
DynamoDB vs RDS
- DynamoDB offers push-button scaling, meaning that you can scale the DB without downtime.
- RDS requires a bigger instance or addition of a read replica to scale (there will be downtime).
Database Migration Services (DMS)
- DMS is a cloud service that makes it easy to migrate relational databases, data warehouses, NoSQL databases, and other types of data stores to a new target datanase or data store.
- Target can be in the cloud or on-premise.
-
Essentially DMS is a server inside of AWS that runs replication software: create source and target connections, tell DMS where to extract from, whether and how to transform, and where to load to.
- Run on an EC2
- DMS creates the tables and associated primiary keys if they do not exist on the target.
- Target tables can be pre-created manually or with AWS Schema Conversion Tool (SCT).
-
Supports homogenous (same to same) and heterogenous (A to B) migrations.
- Heterogenous migration is where you’d want SCT
Caching Strategies
-
Services with caching capabilities
- CloudFront: caching origin at the edge
- API Gateway: HTTP caching
- Elasticache: application-level caching
- DynamoDB: caching table reads
Elastic Map Reduce (EMR)
- EMR is the industry-leading cloud-based big data platform for processing vast amounts of data using open-source tools, such as Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi, and Presto.
- Pricing and Performance: EMR can run petabyte scale analysis at less than half the cost of traditional on-premise solutions and 3 times faster than standard Apache Spark.
- EMR is run atop a cluster. A cluster is a collection of EC2 instances. Each instance is a “node” and assigned a “node type.” EMR installs software components appropriate for each node type, thereby giving each node a role in a distributed application, such as Apache Hadoop.
-
Node Types
- Master Node: manages the cluster. Tracks the status of tasks and monitors the health of the cluster. Every cluster must have a master node.
- Core Node: runs tasks and stores data in the cluster’s Hadoop Distributed File System (HDFS). Multi-node clusters must have at least one core node.
- Task Node: runs tasks and does not store data in HDFS. Task nodes are optional.
- All nodes can communicate with all other nodes.
-
Logs are stored on master node.
- Best practice is to persist logs to S3 to ensure files are available after cluster shuts down or in case of error.
- Persisting logs to S3 must be configured when creating the cluster for the first time.
Virtual Private Cloud (VPC)
Official Resources
Creation Steps
- Create the VPC: name, CIDR block, and tenancy type.
- Create the Subnets.
- Create the Internet Gateway.
- Create custom Route Table for public Subnet(s).
- Point public Subnet’s custom Route Table at the Internet Gateway.
- Configure relevant ACL and Security Group traffic rules.
Default VPC
 AWS does the following to set it up for you:
AWS does the following to set it up for you:
- Create a VPC with a size /16 IPv4 CIDR block (172.31.0.0/16). This provides up to 65,536 private IPv4 addresses.
- Create a size /20 default subnet in each Availability Zone. This provides up to 4,096 addresses per subnet, a few of which are reserved for our use.
- Create an internet gateway and connect it to your default VPC.
- Add a route to the main route table that points all traffic (0.0.0.0/0) to the internet gateway.
- Create a default security group and associate it with your default VPC.
- Create a default network access control list (NACL) and associate it with your default VPC.
- Associate the default DHCP options set for your AWS account with your default VPC.
Custom VPC
- AWS automatically provides a security group, route table, and NACL for a custom VPC.
- AWS does NOT automatically provide a default subnet or internet gateway.
- On Public IPs: When you launch an instance in a default VPC, AWS assigns it a public IP address by default. When you launch an instance into a nondefault VPC, the subnet has an attribute that determines whether instances launched into that subnet receive a public IP address from the public IPv4 address pool. By default, AWS don’t assign a public IP address to instances launched in a nondefault subnet.
VPC
- A VPC is the user’s virtual network, hosted by AWS.
- Used as the network layer for EC2 resources.
- Each VPC is logically isolated from other networks and VPCs.
-
Every AWS account comes with a default VPC, which is preconfigured for immediate use.
- Without a manually-created VPC, user EC2s are hosted in the default VPC.
- If default VPC is deleted, then user needs to contact AWS support to get it recreated. Don’t delete it, dumb dumb.
- VPC can span multiple AZs in a single Region.
- Main reason to create a VPC (and not use default) is granular security controls, such as public and private subnets.
-
Connecting VPC to a Datacenter
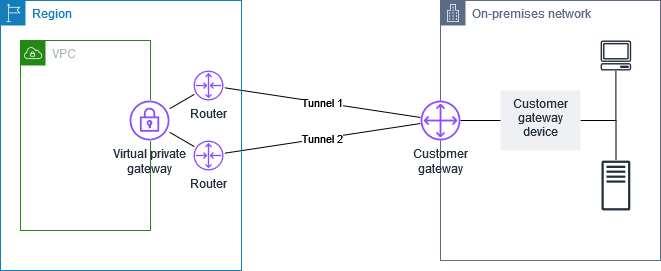
- Virtual Private Gateway: the anchor on the AWS side of a site-to-site VPN connection between an on-premises site and AWS.
- VPN Connection: secure tunnel from datacenter to VPC.
- Customer Gateway: A customer gateway is the anchor on the customer side of an Amazon VPN connection. A physical device or software that sits on datacenter side of connection.
- IPsec Tunnels: default 2. A typical VPN connection uses two different tunnels for redundancy. Both tunnels move between the customer gateway and the virtual private gateway.
- Traffic across the Internet can only flow between public IP addresses in most cases. For a VPN connection, you will need a customer gateway with a public IP address as well as a virtual private gateway with a public IP address, both of which you may be responsible for configuring.
- When connecting a VPN between AWS and a third party site, the Customer Gateway is created within AWS, but it contains information about the third party site e.g. the external IP address and type of routing. The Virtual Private Gateway has the information regarding the AWS side of the VPN and connects a specified VPC to the VPN.
- There are a number of ways to set up a VPN. AWS have a standard solution that makes use of a VPC with a private subnet, Hardware VPN Access, a VPG, and an on-premise Customer Gateway.
-
Peering Connection: VPCs can talk to each other if connected from both sides. Must be within the same region. Peer connections are 1-to-1; no transitive peering (daisy chaining).
- VPCs with overlapping CIDRs cannot be peered.
- Route propagation is a routing option that automatically propagates routes to the route tables so you don’t need to manually enter VPN routes. It’s most common in a Direct Connect setup.
-
Tenancy: VPC can be created on (1) Default; or (2) Dedicated hardware. Performance and cost are both higher on dedicated.
- Once a VPC is set to Dedicated hosting, it can be changed back to default hosting via the CLI, SDK or API. Note that this will not change hosting settings for existing instances, only future ones. Existing instances can be changed via CLI, SDK or API but need to be in a stopped state to do so
-
Private IP Addresses
- Not accessible from regular internet; only from within the VPC.
- Instances on VPC are automatically assigned a Private IP.
-
Public IP Addresses
- Required to access an instance from the general internet.
- Assigned to an instance from AWS’s pool of public IPs. When an instance is terminated and restarted, the public IP is returned to the pool and a new one is chosen.
- Elastic IP Address (EIP)
- An Elastic IP address is a static IPv4 address designed for dynamic cloud computing. By using an Elastic IP address, you can mask the failure of an instance or software by rapidly remapping the address to another instance in your account. An Elastic IP address is allocated to your AWS account, and is yours until you release it.
- An Elastic IP address is a public IPv4 address, which is reachable from the internet. If your instance does not have a public IPv4 address, you can associate an Elastic IP address with your instance to enable communication with the internet. For example, this allows you to connect to your instance from your local computer.
- AWS does not support Elastic IP addresses for IPv6 (as of Jan 2021).
- In order to preserve a Public IP address across termination and restart, user must get an Elastic IP Address (persistent IP address assigned to user account). Charges apply if an EIP is allocated to an account but remains unattached to an instance.
-
Security: Stateful vs Stateless
- Security Groups are stateful: This means any changes applied to an incoming rule will be automatically applied to the outgoing rule. e.g. If you allow an incoming port 80, the outgoing port 80 will be automatically opened.
- Network ACLs are stateless: This means any changes applied to an incoming rule will not be applied to the outgoing rule. e.g. If you allow an incoming port 80, you would also need to apply the rule for outgoing traffic.
CIDR Block
- Classless Inter-Domain Routing (CIDR)
- In VPC context, the CIDR block
- A VPC CIDR block’s subnet mask must be between 16 and 28 (e.g. 10.0.0.0/16)
Subnets
-
A Subnet is a range of IP addresses in a VPC. AWS Resources are launched onto one of a VPC’s Subnets.
- Use a public Subnet for resources that must be connected to the internet (e.g. web servers).
- Use a private Subnet for resources that are not connected to the internet (e.g. DBs).
- VPC must have Subnets assigned to it before EC2 instances can be launched on the VPC.
- Subnets in the same VPC (as subparts of the same IP range) can communicate with each other by default.
- Default CIDR block range for a Subnet is /20, or about 4000 IPs.
- A Subnet is always mapped to a single AZ (although a VPC spans a Region).
- Typically use redundant Public and Private Subnets across different AZs for failure recovery.
-
Public Subnet
- All traffic is routed through the VPC’s Internet Gateway
-
Private Subnet
- For resources that don’t require internet or should be protected, e.g. DB instances.
- Amazon reserves the first four and last IP addresses (five total) in each subnet’s CIDR block. If your subnet CIDR block is too small (e.g. /28), then you may run out of internal private IP addresses.
NAT Gateway
You can use a network address translation (NAT) gateway to enable instances in a private subnet to connect to the internet or other AWS services, but prevent the internet from initiating a connection with those instances.
- You are charged for creating and using a NAT gateway in your account. NAT gateway hourly usage and data processing rates apply. Amazon EC2 charges for data transfer also apply.
- A NAT gateway is preferable to a NAT instance because it is managed by AWS rather than you.
- You can associate exactly one Elastic IP address with a NAT gateway. You cannot disassociate an Elastic IP address from a NAT gateway after it’s created. To use a different Elastic IP address for your NAT gateway, you must create a new NAT gateway with the required address, update your route tables, and then delete the existing NAT gateway if it’s no longer required.
- Each EC2 instance performs source/destination checks by default. This means that the instance must be the source or destination of any traffic it sends or receives. However, a NAT instance must be able to send and receive traffic when the source or destination is not itself. Therefore, you must disable source/destination checks on the NAT instance.
- The following diagram illustrates the architecture of a VPC with a NAT gateway. The main route table sends internet traffic from the instances in the private subnet to the NAT gateway. The NAT gateway sends the traffic to the internet gateway using the NAT gateway’s Elastic IP address as the source IP address.
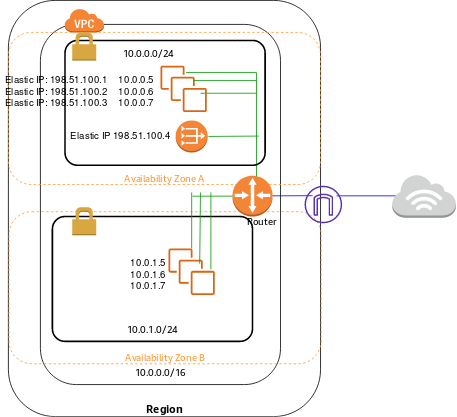
Internet Gateway (IGW)
- IGW is a horizontally scaled, redundant, and highly available VPC component that allows communication between instances in a VPC and the wider internet. No availability risks or bandwidth constraints on VPC network traffic.
- IGW must be attached to a VPC.
- All instances utilizing an IG must have either a Public IP or an EIP.
- Public Subnets’ Route Table must point to the Internet Gateway to allow traffic.
- All network rules (network Access Control Lists and Security Groups) must be configured to allow traffic to and from the relevant VPC instances.
- NAT vs IGW: Attaching an IGW to a VPC allows instances with public IPs to access the internet, while NAT(s) Gateway allow instances with no public IPs to access the internet.
Route Table
- Default Route Table only permits local traffic.
Network Access Control Lists (NACLs)
- VPC comes with a default NACL; default NACL allows all inbound and outbound traffic.
- New NACL denies all inbound and outbound traffic.
- Need to manually enable inbound and outbound traffic, including ”ephemeral ports.”
-
Ephemeral Port:
An ephemeral port is a short-lived port number used by an Internet Protocol (IP) transport protocol. Ephemeral ports are allocated automatically from a predefined range by the IP stack software. An ephemeral port is typically used by the Transmission Control Protocol (TCP), User Datagram Protocol (UDP), or the Stream Control Transmission Protocol (SCTP) as the port assignment for the client end of a client–server communication to a particular port (usually a well-known port) on a server.
On servers, ephemeral ports may also be used as the port assignment on the server end of a communication. This is done to continue communications with a client that initially connected to one of the server’s well-known service listening ports. Trivial File Transfer Protocol (TFTP) and Remote Procedure Call (RPC) applications are two protocols that can behave in this manner. Note that the term “server” here includes workstations running network services that receive connections initiated from other clients (e.g. Remote Desktop Protocol).
- Rules are evaluated in numerical order; first rule trumps later rules.
- NACLs are evaluated before security groups; i.e. NACL-denied traffic will never reach security group for evaluation.
- Each subnet in VPC must be associated with a NACL. If you don’t explicitly associate a subnet with a NACL, then the subnet is automatically associated with the default NACL.
- When blocking specific IP addresses, use NACL not security group.
- NACL to subnet relationship is 1:many, but subnet to NACL relationship is 1:1.
- NACLs are stateless
- TODO: Outbound ports…
AWS Global Accelerator
- Directs traffic to optimal endpoints over the AWS global network in order to achieve improved availability and performance of internet applications.
- Essentially, cut out the potential multi-hops of regular DNS by using a direct line into the AWS backbone.
- GA gives you two static IP addresses to access it. Can also bring your own static IP addresses.
-
Components
- Static IP addresses: two by default and bring your own
- Accelerator: directs traffic to optimal endpoints over the AWS global network. Includes one or more listeners.
- DNS Name: each accelerator is assigned a default DNS name, e.g.
xyz.awsglobalaccelerator.com, that points to the assigned static IP addresses. Generally want to setup DNS records to point fromyourdomain.comto assigned DNS. - Network Zone: services the static IP addresses for the accelerator from a unique IP subnet. Similar to an AZ, it is an isolated unit with its own set of physical infrastructure.
- Listener: processes inbound connections from clients to GA, based on the port (or port range) and configured protocol. GA supports TCP and UDP.
- Each listener has one or more endpoint groups associated with it and traffic is forwarded to endpoints in one of the groups.
- Endpoint Group
- Each endpoint group is associated with a specific Region.
- Endpoint groups include one or more endpoints in the Region.
- Can increase or reduce the percentage of traffic that is directed to an endpoint group using the traffic dial.
- Traffic dial enables performance testing or blue/green deployments.
- Endpoint: traffic-receiving resources such as NLBs, ALBs, EC2s, or Elastic IP addresses.
- An ALB endpoint can be internet-facing or internal.
- Traffic is routed to endpoints based on configuration, such as endpoints weights.
VPC Endpoints
- Take-away: access resources without going through public internet.
- A VPC endpoint enables private connections between your VPC and supported AWS services and VPC endpoint services powered by AWS PrivateLink. AWS PrivateLink is a technology that enables you to privately access services by using private IP addresses. Traffic between your VPC and the other service does not leave the Amazon network. A VPC endpoint does not require an internet gateway, virtual private gateway, NAT device, VPN connection, or AWS Direct Connect connection. Instances in your VPC do not require public IP addresses to communicate with resources in the service.
- VPC endpoints are virtual devices. They are horizontally scaled, redundant, and highly available VPC components. They allow communication between instances in your VPC and services without imposing availability risks.
-
Types
- Interface Endpoints: An interface endpoint is an elastic network interface with a private IP address from the IP address range of your subnet. It serves as an entry point for traffic destined to a supported AWS service or a VPC endpoint service. Interface endpoints are powered by AWS PrivateLink.
- Essentially, attach an ENI to allow access to supported resources.
- Gateway Load Balancer Endpoints: A Gateway Load Balancer endpoint is an elastic network interface with a private IP address from the IP address range of your subnet. Gateway Load Balancer endpoints are powered by AWS PrivateLink. This type of endpoint serves as an entry point to intercept traffic and route it to a service that you’ve configured using Gateway Load Balancers, for example, for security inspection. You specify a Gateway Load Balancer endpoint as a target for a route in a route table. Gateway Load Balancer endpoints are supported for endpoint services that are configured for Gateway Load Balancers only.
- The owner of the service is the service provider, and you, as the principal creating the Gateway Load Balancer endpoint, are the service consumer.
- Gateway Endpoints: A gateway endpoint is for supported AWS services only. You specify a gateway endpoint as a route table target for traffic destined to S3 or DynamoDB only.

VPC Private Link
- Enables VPC-to-VPC communication without flowing through public internet.
- Most effecient way to handle such communication at scale.
- Does not require VPC peering; no route tables, NAT, IGWs, etc.
-
Requires an NLB on the service VPC and ENI on the customer VPC.
- Static address of NLB is opened up to ENI with a Private Link.
Transit Gateway
- Simplify network topology with hub-and-spoke model.
- Allows user to have transitive peering between thousands of VPCs and on-premises data centers.
- Works on regional basis by default but can also work across regions.
- Can work across AWS accounts with Resource Access Manager.
- Can use route tables to limit VPC-to-VPC communication.
- Works with Direct Connect and VPN connections.
- Supports IP multicast (IP multicast is a method of sending Internet Protocol (IP) datagrams to a group of interested receivers in a single transmission. It is the IP-specific form of multicast and is used for streaming media and other network applications. It uses specially reserved multicast address blocks in IPv4 and IPv6.)
VPN CloudHub
- Building on the AWS managed VPN options described previously, you can securely communicate from one site to another using the AWS VPN CloudHub. The AWS VPN CloudHub operates on a simple hub-and-spoke model that you can use with or without a VPC. Use this approach if you have multiple branch offices and existing internet connections and would like to implement a convenient, potentially low-cost hub-and-spoke model for primary or backup connectivity between these remote offices.
Network Costs
- Use private IP addresses over public IP addresses. Traveling in and out of public internet costs more.
- Using a single AZ + private IPs is cost-free but highly risky.
Security
Reducing Security Threats
-
Bad Actors
- Typically automated processes.
- Content scrapers.
- Bad bots.
- Fake user agent.
- Denial of Service (DoS) attacks.
-
Network Access Control List (NACL): (Inbound traffic tables)
- NACL is stateless
- Updates are instantaneous.
- Can create DenyList to block specific bad actors.
- Can create AllowList to allow only trusted actors.
- Firewalls:
- When combined with an ALB, connection terminates at the Load Balancer.
- When combined with an NLB, traffic passes through LB and Client IP is visible e2e, so firewall is effective.
- Can put a Web Application Firewall (WAF) infront of a ALB
- Common exploits are best blocked by WAF (Layer 7)
- IP blocking is best achieved by NACL (Layer 4). Generally weaker because you need to manually keep up with bad IP groups.
- WAF can be attached to a CloudFront distribution. NACL is ineffective in this case because the CF IP is passed, not client.
- CF allows geo-specific blocking if threats originate from a specific country.
Key Management Service (KMS)
- KMS is a service that creates and manages cryptographic keys and controls their use across a wide range of AWS services and in your applications. AWS KMS is a secure and resilient service that uses hardware security modules that have been validated under FIPS 140-2, or are in the process of being validated, to protect your keys.
- A regional managed service to manage encryption and decryption of customer master keys (CMKs).
- CMK is a logical pointer to a key.
- Ideal for encrypting S3 objects and API keys stored in Systems Manager Parameter Store.
- Encrypt and decrypt data up to 4 KB
- Native integration with most AWS services.
- Pricing: Pay per API call
- Audity capability
- Meets FIPS 140-2 Level 2 (government standard)
-
CMK Types
- AWS Managed CMK: free; used by default if you pick encryption in most AWS services. Only that service can use the key directly.
- AWS Owned CMK: used by AWS on a shared basis across many accounts.
- Customer Managed CMK: allows for key rotation; controlled via key policies and keys can be enabled or disabled.
-
Symmetric vs Asymmetric CMKs
- Symmetric CMKs (default)
- Same key used for encryption and decryption.
- Based on AES-256 standard.
- Never leaves AWS unencrypted.
- Must call the KMS APIs to use.
- Used by AWS services integrated with KMS.
- Can be used to generate data keys, data key pairs, and random byte strings.
- Can import your own key material
- Asymmetric CMKs
- Uses a mathematically related public/private key pair.
- Based on RSA and elliptic-curve cryptography (ECC) standard. Generally considered more secure than AES-256.
- Private key never leaves AWS unencrypted.
- Must call the KMS APIs to use the private key.
- Can download public key and use outside AWS.
- Can be used outside of AWS by users who can’t call KMS APIs.
- AWS services that are integrated with KMS do not support asymmetric CMKs.
- Asymmetric CMKS are usually used to sign messages and verify signatures.
- Envelop encryption is more performant because it does not send data over the wire (which happens with standard KMS encryption).
CloudHSM (Hardware Security Modules)
- Use case: keys are subjects to regulatory requirements and therefore need validated control.
- Conforms to FIPS-140-2 Level 3 regulations: includes physical security mechanisms like tamper protection.
- CloudHSM requires you to manage your own keys. Provides a multi-AZ dedicated hardware single-tenant cluster.
- Runs within a VPC.
- No AWS APIs provide access.
- If you lose your keys, the keys are irretrievable.
- Not highly available by default.
- Ideally create one HSM per subnet per AZ, with a minimum of two.
Parameter Store
- Securely manage configuration and secrets within AWS. Cache and secure secrets securely to AWS resources.
- For large applications that manage hundreds of EC2s that spin up and downly automatically.
-
Use case: prevent commit of secrets and configurations.
- Passwords
- Database connections strings
- License codes
- API keys
- Values can be stored encrypted (KMS) or plaintext.
- Separate data from source control
- Can track versions of a value
-
Store parameters in hierarchies
- Each node of a tree can provide all parameters for that node, so you can define a single hierarchy and then provide access by relevant subset.
- Has tight integration with CloudFormation.
Serverless
Lambda
- Pricing: pay only for execution time and compute power.
- Lambda is a compute-on-demand service. AWS Lambda provisions and manages the runtime environemnt used to run the code. No need for the consumer to worry about operating systems, patching, scaling, etc.
-
Use cases
- Event-driven compute service
- Run code in response to HTTP requests received through API Gateway (presumably this is also “event driven”)
- Lambda scales out (not up) automatically (get more lambdas, but not more powerful lambdas).
- Function executions are independent (1 event = 1 function execution).
- Don’t pair with non-serverless resources, obviously.
- Can be hard to debug complex interconnected multi-lambda systems, but AWS X-Ray can help observe such systems.
- Lambdas can act globally; e.g., can back up S3 bucket to other S3 bucket (in another region).
-
Lambda Triggers
- API Gateway
- CloudWatch
- EventBridge
- Alexa Skill
- Cognito
- DynamoDB
- S3
- SQS
- Kinesis
- SNS
- IoT Rule
Serverless Application Model (SAM)
- CloudFormation extension optimized for serverless applications.
- New resource types: functions, APIs, tables
- Supports everything CloudFormation supports (is a Super Set of CF).
- Can run serverless applications locally with SAM Local (lambda only) with Docker.
- Can package and deploy with Code Deploy
-
Trivia
- List Stacks command enables you to get a list of any of the stacks you have created (even those which have been deleted up to 90 days). You can use an option to filter results by stack status, such as CREATECOMPLETE and DELETECOMPLETE. The AWS CloudFormation list-stacks command returns summary information about any of the running or deleted stacks, including the name, stack identifier, template, and status.
Elastic Container Service (ECS)
-
Containers
- A container is a package that contains an application, libraries, runtime, and tools required to run it.
- Run a container on an engine like Docker.
- Provides the isolation benefits of virtualization, but with less overhead and faster starts than traditional VMs.
- Containerized applications are portable and offer consistent environment. Should get same experience whether runnning locally, remotely, etc.
- ECS is a managed container orchestration service.
-
Create clusters to manage fleets of container deployments.
- ECS manages EC2 or Fargate instances.
- ECS schedules containers for optimal placement within cluster.
- Defines rules for CPU and memory requirements.
- Monitors resource utilization.
- Deploy, update, and roll back as necessary
- Pricing: Scheduling and orchestration is… FREE! Pay for underlying EC2s and other resources.
- Native support for CloudTrail and CloudWatch
-
Basic Components
- Cluster: logical collection of ECS resources; either ECS EC2 instances or Fargate instances.
- Task Definition: Defines the application. Similar to a Dockerfile but for running containers in ECS. Can contain multiple containers.
- Container Definition: Inside a Task Definition, it defines the individual containers a task uses. Controls CPU and memory allocation and port mappings.
- Task: Single running copy of any containers defined by a Task Definition. One working copy of an application (e.g. DB and web containers).
- Service: Allows Task Definitions to be scaled by adding tasks. Defines minimum and maximum values.
- Registry: Storage for container images (e.g. Elastic Container Registry (ECR) or Docker Hub). Used to download images to create containers.
-
Fargate: a serverless compute engine for containers.
- Eliminates need to provision and manage servers.
- Specify and pay for resources per application
- Works with ECS and EKS
- Each workload runs in its own kernel.
- Provides isolation and security.
-
When to choose EC2?
- Strict regulatory requirements
- Requires broder customization
- Requires access to GPUs
-
When to choose EKS?
- If you’re already using Kubernetes
-
ECS + ELB
- Distribute traffic evently across tasks.
- Supports all ELBs: ALB, NLB, CLB
- Use ALB to route HTTP (layer 7) traffic
- Use NLB or CLB to route TCP (layer 4) traffic
- Supported by both EC2 and Fargate launch types
- ALB allow dynamic host port mapping, path-based routing, and priority rules.
- ALB is recommended over NLB and CLB
-
Instance Roles vs Task Roles
- Instance roles would share permissions across all the tasks in the cluster.
- Task roles provide more granular permissioning to each task.
Other
VPC Flow Logs
- VPC Flow Logs is a feature that enables you to capture information about the IP traffic going to and from network interfaces in your VPC. Flow log data can be published to Amazon CloudWatch Logs or Amazon S3. After you’ve created a flow log, you can retrieve and view its data in the chosen destination.
-
Flow logs can help you with a number of tasks, such as:
- Diagnosing overly restrictive security group rules
- Monitoring the traffic that is reaching your instance
- Determining the direction of the traffic to and from the network interfaces
- Flow log data is collected outside of the path of your network traffic, and therefore does not affect network throughput or latency. You can create or delete flow logs without any risk of impact to network performance.
- VPC Flow Logs can be created at the VPC, subnet, and network interface levels.
Hypervisors
Opsworks
- OpsWorks is an operational management service, which AWS often classifies as “management tools” (especially in the AWS console). It allows integration with tools like Puppet and Chef.
Amazon FPS & Amazon DevPay
- Using Amazon Flexible Payments Service (Amazon FPS), developers can accept payments on websites. It has several innovative features, including support for micropayments.
- Amazon DevPay instruments two Amazon Web Services to enable a new sort of Software as a Service. Amazon DevPay supports applications built on Amazon S3 or Amazon EC2 by allowing you to resell applications built on top of one of these services. You determine the retail price, which is a mark-up above Amazons base price. Customers pay for your application by paying Amazon. We deduct the base price plus a small commission; then deposit the rest into your Amazon account.
QuickSight
- QuickSight is a cloud-powered business analytics service. It provides visualizations and analysis from multiple data sources.
Cloud9
- Cloud9 is a developer environment, intended as an IDE for AWS developers.
Direct Connect
- Direct Connect is an AWS service for creating a high-speed connection between an on-premises site and AWS.
AWS Shield
- AWS Shield is a managed Distributed Denial of Service (DDoS) protection service that safeguards applications running on AWS. AWS Shield provides always-on detection and automatic inline mitigations that minimize application downtime and latency, so there is no need to engage AWS Support to benefit from DDoS protection.
- Can be an origin for CloudFront.
- CloudFront automatically provides AWS Shield (standard) to protect from DDoS, and it also can integrate with AWS WAF and AWS Shield advanced.
Workspaces
- Amazon Workspaces allows you to provide a desktop service via the cloud. The service allows people throughout the world to take advantage of scalable desktop provisioning.